AI Coding 2026: Hvordan agentdrevet AI-utvikling forandret måten vi leverer tech-prosjekter på

Kort sammendrag:
I 2026 erstattet et norsk byggeselskap to timers manuell renoveringskalkyle med en tretti-minutters AI-drevet gjennomgang - basert på seks historiske eksempler som lærte modellen reglene. Notater fra LANARS i Oslo om hva som faktisk endret seg i programvareutvikling i år: kodeagenter som lagkamerater, små seniorteam som leverer som store, og den nye begrensningen som ikke lenger er ingeniørkapasitet. To casestudier (Lomundal, SelectAI), en praktisk 90-dagers plan for SMB-er, og risikoene som faktisk biter i produksjon. Cirka 13 minutter.
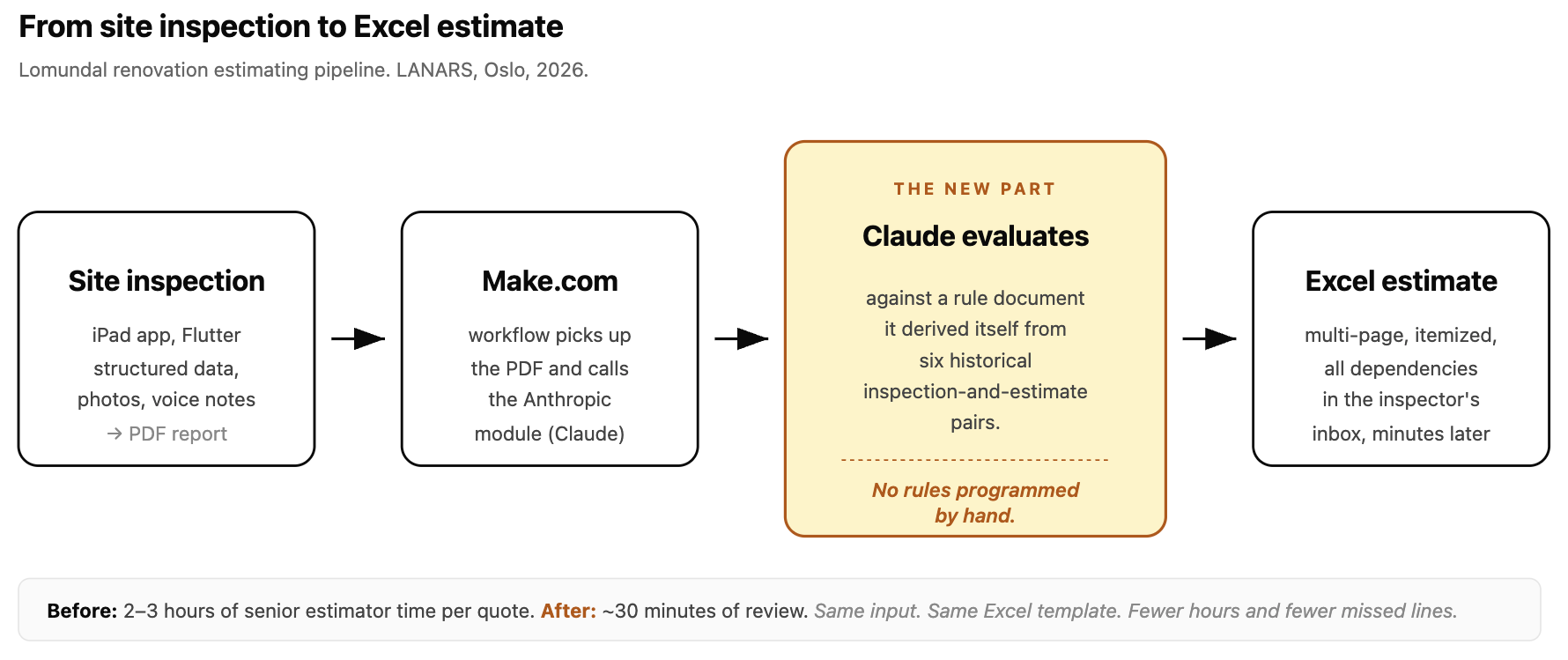
En tirsdag i Oslo. En Lomundal-inspektør lukker iPad-appen etter befaringen av en renovering han nettopp gikk gjennom - tre rom, original ledningsinstallasjon, et bad som har sett bedre tiår. Han trykker «finish» og setter seg i bilen. Når han er tilbake på kontoret, ligger det allerede et flersides Excel-kostnadsestimat i innboksen hans. Poster sortert etter fag, avhengigheter rangert, materialer og timer og uforutsette poster - den typen detaljert tilbud som tidligere tok en senior kalkulatør to-tre timer.
Ingen hos Lomundal eller LANARS programmerte disse reglene. Vi ga Claude seks historiske par - befaringsrapport og estimatet den hadde produsert, seks stykker, det var alt - og ba modellen skrive reglene selv. Dokumentet Claude produserte bor nå inne i en Make.com-arbeidsflyt. Ny befaring inn, Excel ut, før inspektøren er hjemme. Det er det som endret seg i 2026. Ikke et slagord om at datamaskiner tenker. Et norsk byggeselskap har erstattet den arbeidsintensive midten av sin kalkyleprosess med en modell som lærte selskapets egne regler fra seks historiske eksempler, og det er i produksjon nå, gjør arbeidet. Resten av dette innlegget handler om hva som gjorde det mulig, hva vi ser på tvers av prosjektene vi kjører fra kontoret på Fornebu, og hva vi venter av de neste tolv månedene.
Et notat om hvor vi kommer fra
LANARS startet i Norge i 2018 som et lite team som samarbeidet med selskaper i StartUpLab i Oslo. Flaskehalsen for de gründerne var nesten alltid ingeniørkapasitet - backloggen var en liste med «det tar vi senere»-saker, hver ny funksjon betydde en sprint, hver sprint betydde en ansettelsessamtale. I 2026 har flaskehalsen flyttet seg. Ingeniørkapasitet er billig nok nå til at omfang ikke lenger er begrensningen; det er dømmekraft som er det. Det er hele premisset for det som følger.
De tre skiftene
Tre ting skjedde med programvareutvikling samtidig, og de forsterker hverandre. Resten av innlegget arbeider ut konsekvensene.
- Kodeagenter ble lagkamerater. IDE-siden av endringen som alle diskuterer, ofte dårlig.
- Små seniorteam leverer som store team. Endringen i teamøkonomi som har gjort mer for vårt regnskap enn noen av de andre.
- AI er nå forventet inne i selve produktet. Kundesiden av endringen som er gradvis, men umiskjennelig.
Skifte 1. Kodeagenter ble lagkamerater
I 2023 skrev en ingeniør hos LANARS et funksjonsnavn og lot modellen fullføre linjen. I 2026 åpner samme ingeniør en oppgave i Jira, gir den til Claude Code, og ser en fungerende pull request dukke opp tjue minutter senere - med tester, med en beskrivelse av avveiningene modellen vurderte, og med den typen små refaktoreringer en omhyggelig senioringeniør ville gjort underveis. Ingeniørens jobb har ikke forsvunnet. Den har flyttet seg, fra å skrive tegn til å spesifisere intensjon, gjennomgå differ og orkestrere flere parallelle agentsesjoner samtidig. Vi har ingeniører som kjører tre eller fire Claude Code-sesjoner i forskjellige worktrees samtidig: én sender en funksjon, én skriver tester for forrige ukes arbeid, én feilsøker en flaky CI-kjøring, én reviderer avhengighetsoppgraderinger. Resultatet blir fortsatt gjennomgått av et menneske. Genereringen blir det ikke.
Vi gjorde Claude Code til ingeniørstandarden hos LANARS i starten av 2026. Hver ingeniør bruker det hver dag. Nye ingeniører introduseres til det i sin første uke. Produktivitetsforskjellen mellom agentdrevne og ikke-agentdrevne arbeidsflyter er bred nok i 2026 til at det å la det være valgfritt, ærlig talt, var å legge igjen penger på bordet. Vi tok beslutningen om å standardisere, og vi angrer ikke.
Skifte 2. Små seniorteam leverer som store
Det andre skiftet er roligere, men for oss viktigere. Gjennom 2024 og 2025 ansatte vi etter fagdisiplin: backend, frontend, mobil, DevOps. Vi var gode på det. Vi er det fortsatt. Men kostnaden ved å gå utenfor sin disiplin har kollapset i 2026, og ingeniørene som kan ta det skrittet er dramatisk mer verdifulle enn de som ikke kan.
Grunnen er enkel. En ingeniør som forstår hva god arkitektur ser ut som - som kan lese et system, bestemme hva som bør bo hvor, og vurdere om en foreslått endring passer modellen - kan nå legitimt levere på tvers av hele stacken. De mekaniske delene av å arbeide i et ukjent rammeverk eller runtime er nettopp de avgrensede, godt spesifiserte oppgavene der agenter utmerker seg.
Så flaskehalsen på «kan denne personen levere på tvers av web, mobil, embedded og infrastruktur?» er ikke lenger «kan de alle fire i lik dybde?». Den er «kan de resonnere om arkitekturen godt nok til å lede en agent som håndterer detaljene?». Listen for arkitektonisk leseferdighet har gått opp. Listen for stack-spesifikk kunnskap har gått ned.
For oss betyr dette at små seniorteam leverer enorme mengder arbeid. Seks personer på et prosjekt er nok, når hver av disse seks kan lede flere agenter gjennom den stacken arbeidet krever. Vi føler outputen til team to-tre ganger vår størrelse, og det er forholdet vi hører oftest fra gründere som har jobbet med oss i år.
Skifte 3. AI er nå forventet inne i selve produktet
Det tredje skiftet er på kundesiden, og den sterkeste versjonen av påstanden er overdrevet, så vi skal formulere den forsiktig. I 2023 var AI noe man satte fast på et eksisterende produkt som en funksjonsbryter. I 2026 legger kunder - både konsumenter og B2B-operatører - merke til når et produkt de prøver har et smart lag et sted, og et alternativ de nettopp prøvde ikke har det. Smart søk. Et samtaledrevet onboarding-steg. En arbeidsflyt som skriver utkastet til e-posten så mennesket bare redigerer. En agent som gjør den kjedelige midten av en oppgave.
Dette er ikke et hardt krav i hver kategori. Vi later ikke som det er det. Det vi vil si, er at det dukker opp i kundesamtaler oftere enn det gjorde for ett år siden, og retningen er klar. Å sende en SaaS uten en av disse i 2026 er i økende grad et posisjoneringsvalg som må forsvares, ikke en standard som ikke trenger å forsvares. Resten av dette innlegget er hovedsakelig case og konsekvenser av de tre skiftene over. Vi skal fortsette å referere tilbake til dem.
Inne i maskinrommet
Det finnes en form for uærlighet i byrå-innhold om AI som vi vil unngå - rammen om «vi bruker AI for å levere prosjekter» uten spesifisitet, linjen hvert konsulentselskap på jorden skriver i år. Så her er det som faktisk er sant inne i LANARS i 2026, med delene vi er trygge på og delene som fortsatt er i bevegelse. Claude Code er obligatorisk. Hver ingeniør hos LANARS bruker det hver dag, siden starten av 2026, ingen opt-out. Det største løftet er ved starten av nytt arbeid. Når vi setter oss ned til et helt nytt prosjekt, eller en ny funksjon inne i et eksisterende, er tiden spart ikke «litt». Det er flere ganger raskere enn samme team ville beveget seg i 2024. Vi får opp stillas, datamodeller, API-overflater, den kjedelige midten av UI, testharness, deploy-konfigurasjon - alt før lunsj på dag én. Resten av prosjektet er der menneskelig tid går, men tid-til-meningsfull-prototype har kollapset.
Løftet er mer jevnt fordelt på tvers av fagdisipliner enn vi forventet. Backend, frontend, mobil, DevOps - alle beveget seg omtrent i takt. Begrensningen i hver disiplin var å skrive boilerplate, ikke den vanskelige delen. De vanskelige delene er fortsatt vanskelige. De er bare ikke lenger omgitt av timer med mekanisk arbeid. Overvåking betyr mer, ikke mindre. Når programvare blir billigere å skrive, går kostnaden ved ikke å vite hva som skjer i produksjon opp, fordi tingene man ikke ser også blir sendt raskere. Vi investerte i observability - logger, traces, feilsporing, AI-assisterte produksjonsutredninger - for å holde tritt med hastigheten koden endrer seg med.
Arkitektur er den nye gating-ferdigheten. Vi ansetter seniorer. Vi ansetter ikke juniorer i 2026, i hvert fall ikke ennå, og det er et bevisst valg. Gating-ferdigheten i en agentledet arbeidsflyt er arkitektonisk leseferdighet - evnen til å lede, gjennomgå, avvise dårlig output. Den ferdigheten bygges ikke ved å skrive CRUD-endepunkter det første året. Den bygges over et tiår. Vi har en lengre versjon av denne tenkningen på vår AI Strategy 2026-side, inkludert hvordan vi tenker om governance, forskjellen mellom vibe coding og AI-assistert engineering, og senior-only-operativmodellen. Den korte versjonen av det hele: hastighet uten forståelse er gjeld med en frist.
Casestudie én. Lomundal: når seks eksempler var nok
Lomundal er et norsk byggefirma basert i Oslo, som driver med renoveringsprosjekter i regionen. Deres kalkulatører ser på en leilighet eller et hus, bestemmer hva som må byttes ut, hva som kan lappes, hva som er konstruktivt, hva som er kosmetisk, og produserer et detaljert kostnadsestimat. Estimatet må være detaljert - flere fag, avhengigheter mellom poster, materialer, timer, uforutsette - og det må kunne forsvares hvis en kunde stiller spørsmål ved en linje.
Flaskehalsen var ikke befaringen. Vi hadde allerede bygget Lomundal en Flutter-iPad-app som håndterer selve befaringen: strukturert datafangst på stedet, bilder, talenotater, øyeblikkelig PDF-generering. Flaskehalsen var kalkylesteget som kom etter. Vi startet dette prosjektet på samme måte som vi ville startet det i 2024 - ved å forsøke å skrive ut reglene. Vi satt med senior kalkulatører. Vi spurte hvordan de bestemte hva som skulle inkluderes. Vi skrev ting ned. Og vi traff veggen raskt. Det var hundrevis av linjeposter. Det var avhengigheter. Det var «vel, det kommer an på hva annet som er i rommet»-vurderinger. Det var unntak. Regelsettet var for sammenfiltret til å programmere for hånd uten et flerårig prosjekt, og Lomundal trengte ikke et flerårig prosjekt.
Det er her 2026 endrer svaret. I stedet for å programmere reglene, ga vi Claude seks historiske befaringsrapporter parret med de tilsvarende estimatene Lomundal hadde produsert. Seks. Vi sa: finn ut reglene. Skriv dem ned. Det gjorde modellen. Outputen var et langt, strukturert reglementdokument som leste som den samme logikken Lomundals kalkulatører hadde båret rundt i hodet, men eksplisitt. Kalkulatørene leste det, korrigerte delene som var feil, la til de implisitte begrensningene Claude hadde gått glipp av, og leverte det tilbake til oss.
Det dokumentet bor nå inne i Make.com-pipelinen, kalles via Anthropic-modulen. En ny befaring kommer inn som PDF. Make sender PDF-en til Claude med reglementdokumentet vedlagt. Claude produserer linjepostene. En liten etterprosesserer formaterer dem inn i selskapets Excel-mal. Kalkulatørens jobb er ikke lenger «bygg estimatet fra bunnen av». Den er «se gjennom Excelen, juster der Claude tok feil, send den ut». Det som pleide å være en to-til-tre timers oppgave per estimat er nå en cirka trettiminutters gjennomgang. Pipelinen er i tidlig produksjon - færre enn femti estimater har gått gjennom den i skrivende stund - men tidsbesparelsen har vært konsekvent på tvers av batchen.
Den andre fordelen er pålitelighet. Manuell kalkulering på dette kompleksitetsnivået er nettopp den typen arbeid hvor en sliten person klokken fem på ettermiddagen glipper en linje, hopper over en avhengighet eller glemmer å legge på et påslag. Den Claude-deriverte pipelinen produserer den fullstendige outputen hver gang. Kalkulatørens gjennomgang fanger det sjeldne tilfellet der modellen leste rapporten feil; modellen fanger tilfellene kalkulatøren ville ha gått glipp av.
Læringen fra Lomundal går langt utover bygg. Dette er et mønster, ikke en engangshendelse. Nesten enhver SMB har en eller annen versjon av dette lurende i sin operasjon - et regnskapsteam som følger uskrevne regler for å kategorisere en faktura, et ops-team som vet hvilke ordre som skal flagges for gjennomgang, et supportteam som vet når man skal eskalere. Mønsteret er det samme i hvert tilfelle: par historiske eksempler med deres utfall, be Claude skrive reglene, gjennomgå og korriger, deretter operer. Detaljen om seks eksempler bør være overskriften, ikke en fotnote - kostnaden ved å prøve dette på en arbeidsflyt inne i din egen virksomhet er langt mindre enn de fleste operatører antar. Dette er den delen av «AI for SMB-er» vi mener er mest underdiskutert i 2026. Alle snakker om chatbots. Den større nær-tids ROI-en for små operatører er her - bruke AI som et verktøy for å trekke ut og deretter anvende den implisitte logikken virksomheten allerede driftes på.
Casestudie to. SelectAI: en norsk havbruks-oppstart, seks måneder fra konsept til pilot
Den andre casestudien er en oppstartsbedrift, ikke en SMB. Det er det reneste eksemplet vi har på hvordan AI-native utviklingshastighet faktisk ser ut ende til ende. SelectAI er et norsk havbruksoppstartsselskap. Lakselus er ett av de største økonomiske og velferdsmessige problemene i norsk lakseoppdrettsindustri; standard praksis for å måle lusebelastningen er å håve ut femten til tjue fisk per merd hver uke og telle for hånd. Utvalgsstørrelsen er liten nok til at et utbrudd kan være en uke unna før noen ser det i en rapport.
SelectAIs svar er en flytende inn-i-merd-enhet, SelectAI 350, som fanger hver fisk fra tre synkroniserte kameravinkler mens fisken frivillig svømmer gjennom en analysekanal. En datasynsmodell klassifiserer hver fisk - lusekategorier som matcher Mattilsynets egen taksonomi, velferdsindikatorer, juvenil lus som manuelle tellinger ofte går glipp av. Cirka tusen fisk per økt i stedet for femten.
LANARS bygde firmware og programvare i samarbeid med AI Experts, et AI-firma i Grimstad-regionen. Jeg sitter i SelectAIs styre, så jeg vil holde skrytelisten kort - det som er verdt å legge merke til her er tidslinjen. Fra konsept til en fungerende maskinvareenhet, validert programvare, en annoteringspipeline brukt av biologer, og piloter på ekte norske oppdrettsanlegg: seks måneder. Teamet er tre personer. I 2024 ville et prosjekt med dette omfanget tatt halvannet år med et team dobbelt så stort. Det interessante designvalget er ett vi vil bruke et øyeblikk på, fordi det fanger skifte 2 (små seniorteam) og skifte 3 (AI inne i produktet) samtidig: maskinvaren ble designet rundt modellen, ikke omvendt.
Tri-vinkel-kameraoppsettet eksisterer fordi modellen trenger tre synkroniserte visninger for å unngå å dobbelttelle den samme laksen på tvers av venstre og høyre side. Vi bygde riggen rundt det modellen krevde - patent pending, forresten. Det er en liten ting på overflaten, men en stor en under: i 2024 ville vi bygget den åpenbare enkelt-kamera-riggen og akseptert datakvalitetstapet som en fysikkens lov. I 2026 har modellen vetorett på maskinvarespesifikasjonen fordi modellen er produktet. Valideringssyklusen er rask av samme grunn hvert annet 2026-prosjekt er raskt: kostnaden ved å bygge ett verktøy til er liten. Når SelectAI-teamet trenger en tilpasset visning av hvordan modellen presterte på en bestemt merd, sendes den visningen samme uke, ikke i et kvartals planlegging. Annoteringsverktøyet selv, brukt av biologer på tvers av flere norske lokasjoner, ble bygget og revidert på samme syklus.
Vi vil nevne tre trekkraftspunkter og stoppe der, fordi læringen er i hastigheten, ikke i premieskapet: femten tusen fisk analysert til dato, feltvalidering hos Varde Fiskeoppdrett og Lerøy under ekte vinterforhold, og støtte fra Innovasjon Norge. Hovedmålet - Mattilsynet-godkjenning som et automatisert lustellingssystem, som ville erstatte manuelle tellinger på regulatorisk nivå - sikter mot slutten av 2026. Versjonen av denne historien vi vil at operatører og gründere skal lese, er: lite team, kort syklus, AI i byggeprosessen og i produktet samtidig, maskinvare designet rundt modellen, feltvalidering innenfor år én. Ingen av det var rutine i 2024. Alt er rutine i 2026.

Hva dette betyr for gründere
Den største endringen for en oppstartsgründer i 2026 er kostnaden ved å prøve. «Test ideen»-stadiet av en oppstart pleide å koste seks måneder og mesteparten av en seed-runde. I mange kategorier koster det nå to uker og et lite stykke av en seed-runde. Mønstrene som tok oss et år å bygge for StartUpLab-team i 2018 er helgeoppgaver nå. Det har produsert to grunderkohorter samtidig, og det er verdt å navngi begge fordi de vil definere støygulvet for oppstartsmarkedet de neste to årene.
En kohort er wannabe-vibekoderen - solo-gründere med koffein og en kodeagent, som sender prototyper som ikke løser et reelt problem. De fleste varer ikke et kvartal. Reell støy i markedet på grunn av dette: investorer ser flere pitches, ansettelser er høyere, oppmerksomhet er vanskeligere å få. Den andre kohorten er gründeren som ekte verdi nå når markedet raskere for. Dette er folk som hadde det rette problemet og alltid skulle bygge det rette - de måtte bare vente seks måneder på en MVP. Nå venter de seks uker. Tilbakemeldingssløyfen starter tidligere. De gode ser ut som SelectAI: ekte partnere, ekte penger, ekte validering innen år én.
For gründere som henter kapital i 2026 - her er en konkret innramming vi forventer at investorer vil konvergere mot innen seks måneder. En oppstart hvor MVP-en tok mer enn åtte uker, bør være klar til å forklare hvorfor - enten omfanget var uvanlig dypt (regulert industri, ny maskinvare, ekte ML), eller noe var galt med hvordan teamet nærmet seg byggingen. Benchmarken har strammet seg, og den vil fortsette å stramme seg. Den strategiske implikasjonen er ubehagelig. Listen for å bli lagt merke til er høyere fordi støyen er høyere; listen for å være ekte er lavere fordi det å sende er billigere. Distribusjon, smak og evnen til å snakke med kunder - delene AI ikke gjør - er den faktiske begrensningen nå. Ingeniørkapasitet er det ikke.
Hva dette betyr for operatører
For en liten eller mellomstor virksomhet som driver en eksisterende operasjon, er svaret annerledes, og uten tvil mer umiddelbart lønnsomt. Lomundal-historien er malen. Finn én repetitiv, godt definert operasjon inne i virksomheten din - vanligvis en som er flaskehalset på en seniors tid. Kalkulasjon, klassifisering, utkast, triagering, rapportering, oppsummering. Velg den med de reneste inputene og outputene. Få en Make.com- eller tilsvarende arbeidsflyt i gang. Hardkode prompten. Kople én kunde eller ett internt team til den. Mål i en måned.
Vi ser to feilmoduser konsekvent.
Den første er å velge det blendende use-caset først. Det blendende use-caset er som regel kundevendt og høyrisiko. Det er det feile stedet å starte. Start med den kjedelige interne arbeidsflyten som ingen er begeistret for. En mangelfull kundevendt AI-funksjon flauer deg foran brukerne. En mangelfull intern arbeidsflyt flauer deg bare foran deg selv, som er det bedre klasserommet.
Den andre er å ikke måle. AI-funksjoner som ikke er instrumentert fra dag én råtner stille. Modelldrift, prompt-regresjoner, kanttilfeller som dukker opp en gang i måneden - disse er ikke synlige uten observability. Den samme disiplinen som betyr noe for enhver produksjonsservice betyr noe for AI-arbeidsflyter, og uten tvil mer, fordi feilmodusene er merkeligere og mindre mekaniske.
Når det gjelder ROI, en ærlig observasjon i stedet for et løfte. På tvers av SMB-engasjementene vi har kjørt i 2025 og 2026 som ligner Lomundal i form - avgrenset intern arbeidsflyt, smale inputs, smale outputs - ser vi vanligvis operasjonstidreduksjoner i området fem til ti ganger, og tilbakebetaling på byggingen innen én til tre måneder. Variansen er bred. Prosjektene med de reneste historiske dataene og den mest tålmodige gjennomgangssyklusen sitter i den høye enden av spekteret; prosjektene som prøver å gjøre for mye samtidig sitter i den lave enden. Behandle disse tallene som en pekepinn, ikke et tilbud.
2026-stacken (CTO-notat)
Hvis du er CTO og velger teknologi i 2026, her er den korte, opinion-bærende versjonen. CEO-er uten en CTO i rommet kan hoppe videre uten å gå glipp av noe viktig.
For web-siden er prinsippet å velge et rammeverk med førsteklasses støtte for streaming og delvis rendering, deployet på en plattform som gir full Node.js (ikke bare edge), lange funksjons-timeouts, og instansgjenbruk for AI-arbeidsbelastninger. Dette er ikke eksotiske krav i 2026; det er minstemål.
For modelltilgang er den høyeste-leverage-beslutningen å rute gjennom en modell-gateway i stedet for direkte til én leverandør. Leverandørstrenger gjør modellbytte til en én-linjes endring. Fallback-ruting håndterer leverandør-hikst. Null databevaring bør være standard. Forent fakturering betyr færre fakturaer å jage. Gatewayen er den delen av enhver AI-stack som har betalt seg raskest tilbake i våre prosjekter, med god margin.
For lagring, foretrekk managed Postgres, managed Redis for hot-path-caches, og managed objektlagring for opplastninger, alt provisjonert gjennom én markedsplass slik at miljøvariabler lander der de skal uten manuell rørlegging. For autentisering, en managed identitetstjeneste med middleware-baserte session-sjekker. For mobil, et kryssplatformrammeverk som det samme agentdrevne ingeniørmønsteret passer naturlig til; vi har brukt Flutter på både Lomundal og SelectAI av den grunn.
Denne stacken er opinion-bærende fordi opinionene tjener tiden tilbake. Et team som velger noe annet kan absolutt lykkes - men de vil bruke gründer-timer på infrastrukturbeslutninger ingen husker om to år. Vi vil heller bruke de timene på produktet.

Der ting går i stykker
Risikoene i 2026 er ikke risikoene folk bekymret seg for i 2023. «Vil AI erstatte utviklere» er ikke en 2026-samtale. De reelle risikoene er roligere, og de handler om disiplin mer enn teknologi. Listet omtrent i den rekkefølgen de oftest biter norske operatører vi jobber med.
Datastyring. For norske selskaper som betjener regulerte bransjer - helse, finans, alt som berører GDPR-landskapet - må spørsmålet om hvor data går når det sendes til en LLM besvares før den første prototypen sendes. De to praktiske standardene: rut gjennom en gateway med null databevaring, og velg leverandører med eksplisitte databehandleravtaler og regionale deploymentalternativer. Vi har hatt denne samtalen med flere norske SMB-er, og det er sjelden så komplisert som deres juridiske team først frykter, men det må besvares eksplisitt, ikke implisitt. Risikoen er ikke at regulatoren tar deg; risikoen er å sende en funksjon du senere må rive ut fordi den ikke kan forsvares.
Hallusinasjoner i produksjons-AI-funksjoner. Dette er risikoen de fleste team undervurderer i sin andre AI-funksjon, etter at den første fungerte. Produksjonsmodeller vil, av og til, produsere et selvsikkert svar som er feil. Mønsteret som demmer opp for dette er det samme som demmer opp for hver annen pålitelighetsrisiko: avgrens overflaten av hva modellen får lov til å si, forankre svarene i hentbar data der det er mulig, valider outputs mot et skjema før de når en bruker, og instrumenter slik at du ser feilmodusene tidlig. Hallusinasjoner er ikke et forsknings-stadium-problem; de er et ingeniørproblem med kjente avbøtende tiltak, og de bør være et sjekkliste-punkt, ikke et håp.
Kode uten forståelse. Den vanligste feilmodusen i team som tar i bruk agenter uten disiplin er å sende kode de ikke fullt ut forstår. Kompilerer, tester passerer på overflaten, og seks uker senere går noe subtilt i stykker i produksjon med ingen på teamet i stand til å lese det ødelagte raskt nok til å fikse det. Avbøtelsen er senior-only-modellen vi skrev om ovenfor - anmeldere som kan holde tritt med raten av generert kode uten å miste forståelsen. Hastighet uten forståelse er gjeld med en frist.
Leverandør-lock-in som en margin-sak. I 2023 var dette en irritasjon. I 2026, med ukentlige modellutgivelser og prisforskjeller av størrelsesordener mellom kapasitetsnivåer, er det en margin-sak. Arkitekt hvert prosjekt slik at leverandør og modell er konfigurasjonsverdier, ikke kode. Kostnaden ved å gjøre dette er liten; kostnaden ved å ikke gjøre det akkumulerer månedlig.
Den nye vakttjenesten. AI-generert kode som ødelegges i produksjon trenger et menneske som kan lese feilen, diffen, sporet og modellens resonnement, og bestemme hva som skal rulles tilbake. Vakthavendes jobb har skiftet fra «fiks det» mot «vurder det». Det tradisjonelle senioringeniør-ferdighetssettet har blitt mer verdifullt, ikke mindre.
En praktisk 90-dagers plan
Hvis du driver en SMB og vil teste hva AI kan gjøre for operasjonen din, her er formen på de første nitti dagene som fungerer mest konsekvent for oss.
Dag 1 til 14. Velg én arbeidsflyt. Den ene mest repetitive, godt definerte, lav-risiko-arbeidsflyten inne i virksomheten. Skrive utkast til et svar, oppsummere en post, tagge en opplasting, generere et estimat fra en rapport. Unngå den kundevendte. Unngå den som «ville vært fantastisk hvis den fungerte». Start med den kjedelige hvis inputs og outputs du kan beskrive i et avsnitt.
Dag 15 til 30. Send den minste mulige versjonen. Make.com eller tilsvarende. Hardkode prompten. Én intern bruker. Instrumenter hver input, hver output, hvert modellkall. Ikke hopp over instrumenteringen. Det er hele spillet.
Dag 31 til 60. Legg til datalaget. Hvis arbeidsflyten drar nytte av dine historiske data - og det gjør den nesten alltid, som Lomundal viser - gi Claude historiske eksempler og la modellen utlede reglene. Gjennomgå med fageksperten. Korriger de åpenbare feilene. Lever dem tilbake til pipelinen.
Dag 61 til 90. Industrialiser. Versjoner prompten. Legg til en backup-modell. Flytt reglementdokumentet inn i versjonskontroll. Legg til et lite evalueringsharness som kjører mot et frossent sett av historiske eksempler hver gang prompts eller regler endrer seg. Dokumenter hva arbeidsflyten gjør og hva den ikke gjør.
Innen dag nitti gjør arbeidsflyten ekte arbeid, infrastrukturen er der til å legge til de neste ti arbeidsflytene uten å bygge om, og teamet har internalisert mønsteret.
Ofte stilte spørsmål
- Hva betyr egentlig «AI-native utvikling» i 2026?
To ting samtidig. Ingeniørarbeidsflyten bruker AI-verktøy - kodeagenter, AI-kodegjennomgang, AI-drevet testing - som daglig standard, ikke som et eksperiment. Produktet selv sendes med AI som en primær kapabilitet - chat, retrieval-augmented search, autonome arbeidsflyter - i stedet for som et påklistret tillegg.
- Hvor lang tid tar det å bygge en MVP i 2026 sammenlignet med 2024?
To til fem ganger raskere i vår erfaring, avhengig av omfang. SelectAI sendte et fungerende maskinvare-pluss-programvare-produkt på seks måneder med et team på tre - et prosjekt som ville vært halvannet år i 2024 med et team dobbelt så stort. For rene programvare-MVP-er er tre til åtte uker realistisk for det som pleide å ta tre til seks måneder. Resten av tiden går til produktdømmekraft, kundesamtaler og design - ikke ingeniørarbeid.
- Kan AI bygge MVP-en min uten ingeniører?
For en ekte produksjons-MVP - med autentisering, betalinger, dataeierskap, en vei til å skalere - nei. AI-verktøy akselererer ingeniørarbeid, men et menneske trengs for å ta arkitektoniske valg, gjennomgå endringer, eie sikkerhet og vurdere produktavveininger. Et realistisk 2026-tall er én ingeniør (eller én teknisk gründer) som gjør arbeidet til et 2023-team på tre til fem.
- Er AI-generert kode trygt å sende til produksjon?
Med en normal ingeniørarbeidsflyt - gjennomgang, tester, CI, observability, vakttjeneste - ja. AI-generert kode sendes til produksjon hver dag hos selskaper av alle størrelser i 2026, inkludert vårt. Mønsteret som svikter er «send uten gjennomgang». Mønsteret som fungerer er det samme som fungerte før AI: små differ, tester, gjennomgang, observability.
- Hvilken modell bør jeg velge for produktet mitt?
Rut gjennom en gateway. Velg en frontier-modell for kvalitetskritiske stier, en mindre raskere billigere modell for høy-volum lav-innsats-stier. Den spesifikke vinneren på kvalitet og pris endrer seg månedlig; det arkitektoniske svaret - modell som en konfigurasjonsverdi, ikke en kodeendring - gjør det ikke.
- Trenger vi å trene vår egen modell?
Nesten aldri. På tvers av prosjektene vi har sendt eller revidert i 2025 og 2026 har færre enn én av tjue hatt nytte av å trene en modell fra bunnen av. Resten får mer ut av frontier-modeller kombinert med god retrieval, gode prompts og god UX. Unntakene er domenespesifikke vertikaler som opererer i stor skala med proprietær data - SelectAIs datasynsmodell er ett, fordi modeller utenfor hyllen ikke vet hvordan en norsk lakselus ser ut.
- Hva er forskjellen mellom SEO og AEO?
SEO (søkemotoroptimalisering) rangerer innhold i klassiske søkemotorresultater. AEO (svar-motor-optimalisering) får innhold sitert av AI-svarmotorer - Perplexity, ChatGPT, Claude, Google AI Overviews - når de svarer på brukerspørsmål. AEO favoriserer klare faktabaserte utsagn, eksplisitte spørsmål-og-svar-blokker, godt strukturerte overskrifter, og entitetsrik innhold en modell kan trekke ut og sitere.
- Hvor i produktet vårt bør vi starte med AI?
Med den kjedelige interne arbeidsflyten ingen er begeistret for. Den blendende kundevendte funksjonen er høyrisiko; en mangelfull AI-funksjon vist til kunder skader tilliten. En mangelfull intern arbeidsflyt flauer deg bare foran deg selv, som er det bedre klasserommet.
Ingeniørkapasitet pleide å være begrensningen. Det er det ikke lenger. Begrensningen er det som alltid var vanskeligere - å vite hva man skal bygge.
Ta en titt på andre artikler

24.05.2024
KundeveiUtforske alle fasene bedriften eller personen går gjennom når det kommer til teknologisk prosjektutvikling, hvorfor det kan være nødvendig, hvordan velge riktig leverandør og hvordan du får maksimal avkastning fra investeringen din.Les mer
13.06.2023
Alt om forretningsstrategier: Typer, fordeler og ulemper, og eksemplerDet spiller nesten ingen rolle hvilken sektor du jobber i, for konkurransen er intens i alle sektorer. Bedrifter prøver konstant å oppnå fordeler ved å kutte kostnader, innføre unike løsninger eller investere i ekspansjon. Alle disse trekkene kan være kraftige, men de må være innenfor en klar, veldefinert ramme som kan basere strategien på bedriftens ressurser. Den rammen kalles en forretningsstrategi. La oss se hvordan det fungerer.Les mer
31.05.2023
Fra Smarte Hjem til Smarte Byer: Påvirkningen av AI og IoT i Det Urbane LivDe siste årene har kunstig intelligens (AI) og tingenes internett (IoT) tatt hovedscenen og gitt oss et glimt av en verden der vi kan leve grønt, nyte bedre offentlig og personlig sikkerhet og kvitte oss med irriterende trafikkork! Nå lurer du nok på: "Hvordan kan AI og IoT forbedre det urbane livet i smarte byer?" Fortsett å lese for å finne ut.Les mer